K-means |
It is a clustering algorithm based on unsupervised learning. The main goal of this algorithm is to find groups in the data. Each group is called a cluster and has a centroid. The letter K is used to represent the number of groups, and therefore, the number of centroides. It is an iterative algorithm to group data in clusters with similar properties. Below you can see the three steps of the K-means algorithm. You can search videos on the Internet to better understand this algorithm.
Es un algoritmo de agrupamiento basado en aprendizaje sin supervisión. La meta principal de este algoritmo es encontrar grupos en los datos. Cada grupo es llamado racimo (cluster) y tiene un centroide. La letra K se usa para representar el número de grupos y por lo tanto el número de centroides. Este es un algoritmo iterativo para agrupar de datos con propiedades similares. Debajo se muestran los tres pasos del algoritmo de K-means. Usted puede buscar videos en la Internet para entender mejor este algoritmo.
|
K-means++ |
It is an initialization method that can improve the performance of the algorithm.
Este es un método de inicialización que puede mejorar el desempeño del algoritmo.
|
| Problem 1 |
| Create a Dialog application using Wintempla called Wine to classify a synthetic database using the K-means algorithm. Cree una aplicación de Diálogo a usando Wintempla llamada Wine para clasificar una base de datos sintética usando el algoritmo de K-means. |
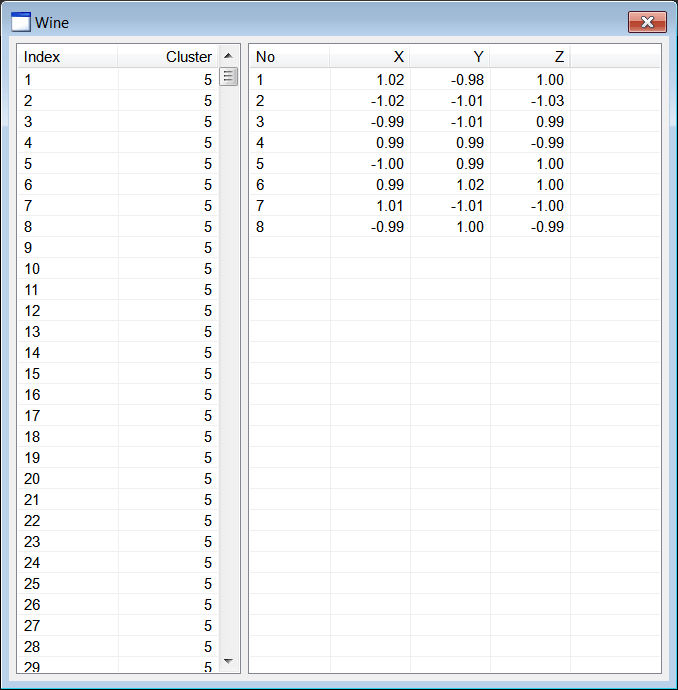
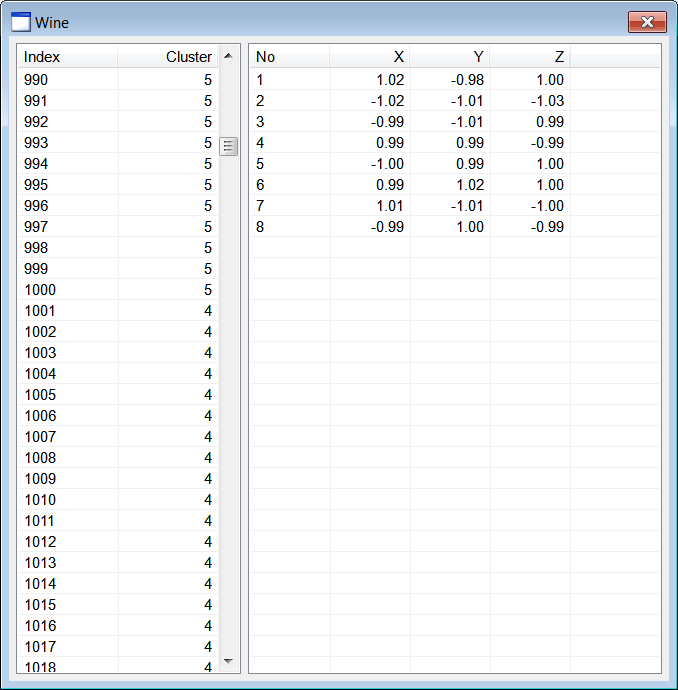
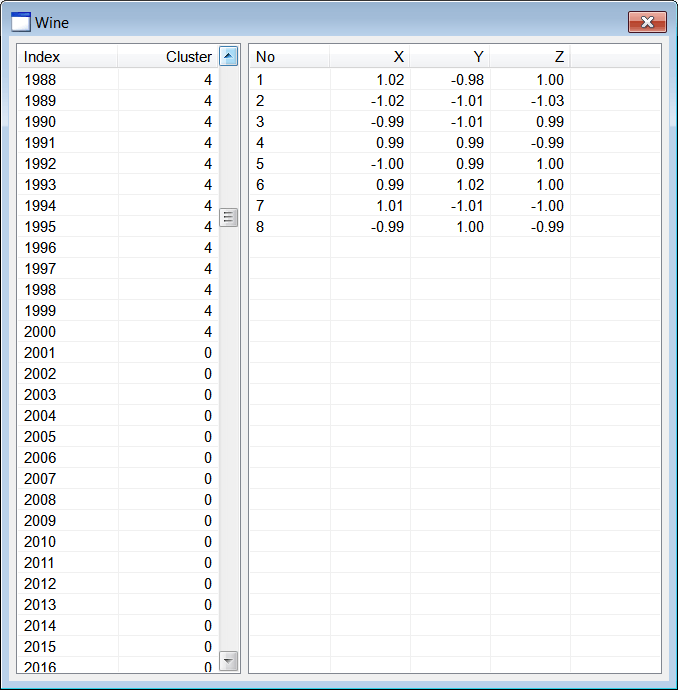
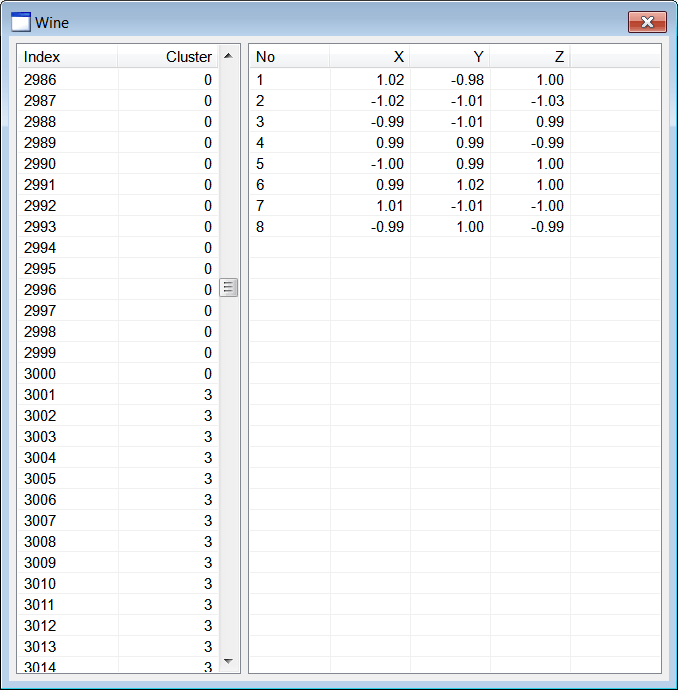
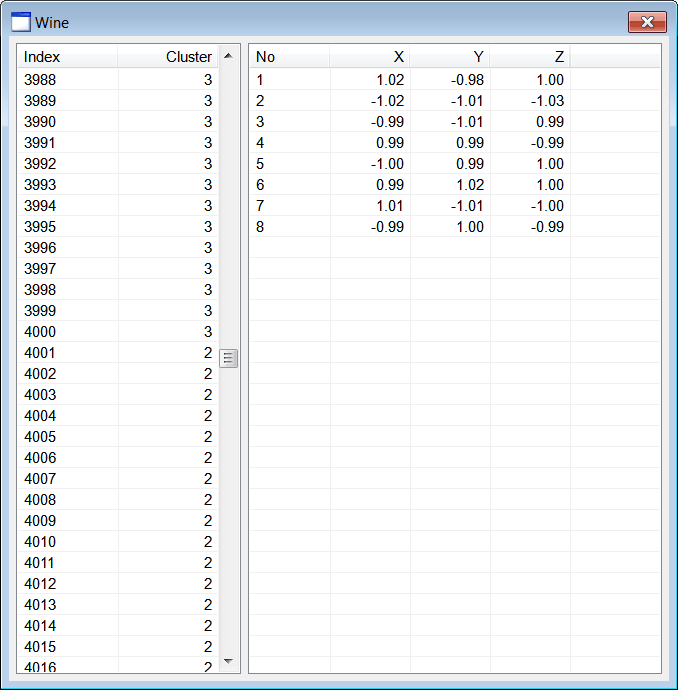
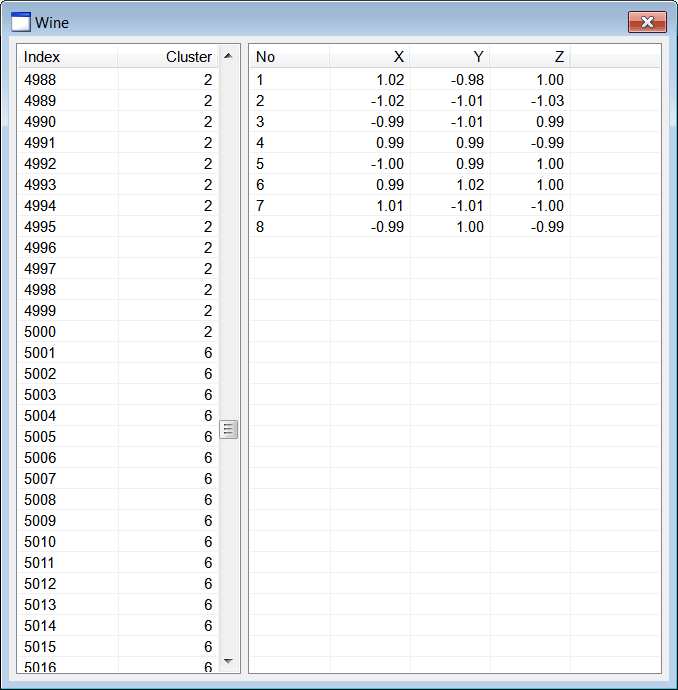
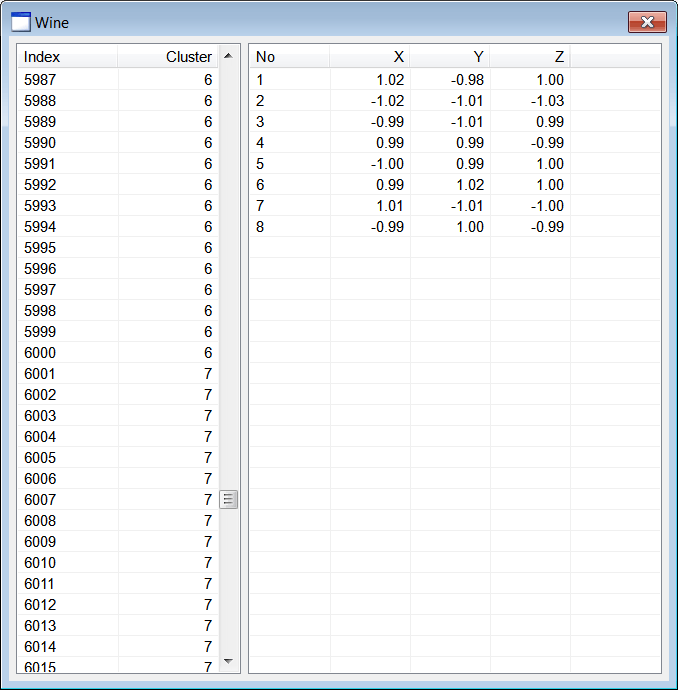
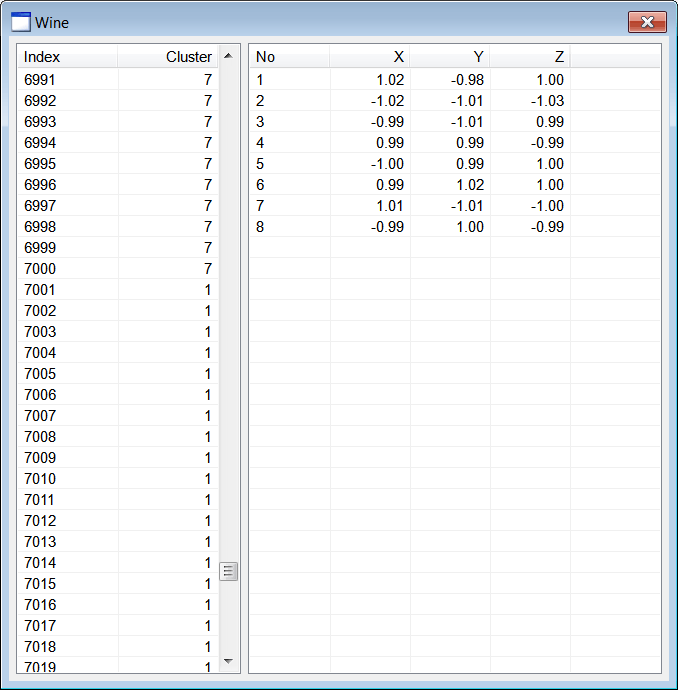
| Wine.h |
| #pragma once //______________________________________ Wine.h #include "Resource.h" #define CLUSTER_SIZE 1000 class Wine: public Win::Dialog { public: Wine() { randGen.seed(::GetTickCount()); } ~Wine() { } std::mt19937 randGen; void CreateCluster(double centerX, double centerY, double centerZ, double radius, size_t pointCount, MATRIX& out_data); . . . }; |
| Wine.cpp |
| . . . void Wine::Window_Open(Win::Event& e) { //________________________________________________________ lvCluster lvCluster.Cols.Add(0, LVCFMT_LEFT, 100, L"Index"); lvCluster.Cols.Add(1, LVCFMT_RIGHT, 100, L"Cluster"); //________________________________________________________ lvCentroid lvCentroid.Cols.Add(0, LVCFMT_LEFT, 80, L"No"); lvCentroid.Cols.Add(1, LVCFMT_RIGHT, 80, L"X"); lvCentroid.Cols.Add(2, LVCFMT_RIGHT, 80, L"Y"); lvCentroid.Cols.Add(3, LVCFMT_RIGHT, 80, L"Z"); //________________________________________________________ size_t i; MATRIX dataset; MATRIX cluster; //________________________________________________________ 1. Cluster at (1, 1, 1) CreateCluster(1.0, 1.0, 1.0, 0.95, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 2. Cluster at (-1, 1, 1) CreateCluster(-1.0, 1.0, 1.0, 0.85, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 3. Cluster at (1, -1, 1) CreateCluster(1.0, -1.0, 1.0, 0.97, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 4. Cluster at (1, 1, -1) CreateCluster(1.0, 1.0, -1.0, 0.94, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 5. Cluster at (-1, -1, 1) CreateCluster(-1.0, -1.0, 1.0, 0.96, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 6. Cluster at (1, -1, -1) CreateCluster(1.0, -1.0, -1.0, 0.86, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 7. Cluster at (-1, 1, -1) CreateCluster(-1.0, 1.0, -1.0, 0.93, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 8. Cluster at (-1, -1, -1) CreateCluster(-1.0, -1.0, -1.0, 0.92, CLUSTER_SIZE, cluster); for (i = 0; i < CLUSTER_SIZE; i++) dataset.push_back(cluster[i]); //________________________________________________________ 9. Execute K-means algoritm MATRIX centroid; vector<int> result; Math::KMeans kmeans; kmeans.CreateClusters(100, dataset, 8, centroid, result); //________________________________________________________ 10. Display cluster wchar_t text[64]; const size_t rowCount = result.size(); for (i = 0; i < rowCount; i++) { _snwprintf_s(text, 64, _TRUNCATE, L"%d", i+1); lvCluster.AddItem(text, 0); // _snwprintf_s(text, 64, _TRUNCATE, L"%d", (int)result[i]); lvCluster.SetItemText(i, 1, text); } //________________________________________________________ 11. Display centroids for (i = 0; i < 8; i++) { _snwprintf_s(text, 64, _TRUNCATE, L"%d", i+1); lvCentroid.AddItem(text, 0); //_______________________ X _snwprintf_s(text, 64, _TRUNCATE, L"%.2f", centroid[i][0]); lvCentroid.SetItemText(i, 1, text); //_______________________ Y _snwprintf_s(text, 64, _TRUNCATE, L"%.2f", centroid[i][1]); lvCentroid.SetItemText(i, 2, text); //_______________________ Z _snwprintf_s(text, 64, _TRUNCATE, L"%.2f", centroid[i][2]); lvCentroid.SetItemText(i, 3, text); } } void Wine::CreateCluster(double centerX, double centerY, double centerZ, double radius, size_t pointCount, MATRIX& out_data) { std::uniform_real<double> distribution(-radius, radius); if (out_data.size() != pointCount) out_data.resize(pointCount); const double sqrad= radius*radius; double distance; for (size_t i = 0; i < pointCount; i++) { out_data[i].resize(3); while (true) { out_data[i][0] = distribution(randGen); out_data[i][1] = distribution(randGen); out_data[i][2] = distribution(randGen); distance = out_data[i][0]*out_data[i][0] + out_data[i][1]*out_data[i][1] + out_data[i][2]*out_data[i][2]; if (distance < sqrad) break; } out_data[i][0] += centerX; out_data[i][1] += centerY; out_data[i][2] += centerZ; } } |